Introduction
The term vibe coding had its first anniversary last week. It has been little over a year since Andrej Karpathy, former Tesla AI director and OpenAI co-founder, posted on X describing what he called "a new kind of coding." During the recent year, the way coding is done has changed a lot. We have seen the rise of both reasoning models and coding agents. Software engineers are also more divided than ever, with some calling it a bubble, while others see it as the beginning of the end of the profession.
During the last year I've been trying to figure out where I stand. I have explored both ends of the spectrum and have worked with different tools. I'm generally both positive and optimistic about using LLMs for coding. However, I have at the same time realized quite a lot about how I learn, write code, and solve problems when using LLMs.
In this blog, I'd like to share some lessons I've personally had regarding LLM usage when coding. There is a ton to say about this subject, but I have chosen to narrow it down for this blog. I have chosen to split it up into two major lessons I have had:
-
Thinking in abstraction layers: understanding that LLM-assisted coding is not one abstraction, but several, each with additional trade-offs.
-
The difference between reading and writing code: recognizing that these are fundamentally different skills, and that LLMs affect each ability differently.
I'm sharing these ideas because I've found them useful in giving me a framework for choosing how I code based on what matters:
-
If the purpose is to learn a programming language, I want to understand the syntax and learn how to write code, then outsourcing the writing to an LLM would completely miss the point.
-
If the whole purpose is to quickly ship an MVP, I can decide to use a quicker agentic workflow, since the focus lies on iterating on the product so we can decide what to actually build.
I hope this blog will awaken some thoughts in you as a reader, because this is hardly an objective matter. We learn, read and write code in different ways.
What Happened in 2025?
Before we begin, I would like to spend some time on recapping the recent year in LLMs. For an in-depth recap, I recommend 2025: The year in LLMs by Simon Willison. Here's what mattered most for coding specifically.
Every major AI lab released "reasoning" models in 2025. These are models that think through problems step-by-step rather than generating answers immediately. For coding, the improvement was significant: they could hold larger context in mind and make more coherent decisions across multiple files.
Combining reasoning with tool use gave us coding agents: systems that can write code, execute it, inspect results, and iterate. Arguably one of the more important moments of 2025 was when Anthropic released Claude Code alongside Claude Sonnet 3.7 in February. Coding agents automated the entire manual cycle of promting, copy output, run it, hit an error and paste it back. On top of this, context windows kept growing and token prices dropped dramatically, with Google's Gemini models shipping million-token windows that made it feasible to feed entire codebases into a single prompt.
The developments happened so quickly that most of us were left unsure what to actually do with the tools we were offered. Andrej Karpathy, who had introduced vibe coding earlier in the year, ended it by writing that "I've never felt this much behind as a programmer". How do we as software engineers make sense of all this progress?
The Three Layers of Abstraction
I would like to begin with an idea that considers software engineering a series of abstractions. It says the following:
Throughout its short history, software engineering has been a series of abstractions enabled by technological advancements, which has made it quicker and easier to tell a computer what to do
In the beginning, we used assembly (pure machine instructions) to tell computers what to do. It worked, but it scaled very badly. Then came C, which made it possible to write programs using something resembling human language. This was the first major abstraction. Suddenly we could build operating systems and embedded systems within realistic engineering timescales. Some time later, Python and other high-level frameworks further accelerated development with better tooling and more forgiving syntax. Each of these steps allowed us to write software faster.
People have taken this idea further and have called LLM-based coding the next major abstraction in software engineering. When taking a closer look, we can see that LLM-based coding is not one, but a series of abstractions that can be divided into different categories. I think it's important to be aware of what level you are working on, and what the trade-offs are for you as a coder. For simplicity's sake, I like to split it up into three layers. Let's go through each one.
1. Tab autocomplete
This is the widely known Github Copilot or Cursor tab autocomplete functionality. There is an LLM analyzing the current file and autocompleting the current line, or even several lines at once. In many cases it's very effective at picking up the correct context and suggests what you want to write.
Although the long-term side-effects on coding ability of using tab autocomplete are still uncertain, I personally feel like the trade-off when I code with tab autocomplete is minimal. You are still thinking through almost every line. Most of the time the autocomplete feature correctly predicts the next line, but in several cases I have found that I wanted to write the code in a different way. The only noticeable negative effect I have experienced from using this is occasionally forgetting the syntax of the programming language, which is why I often try to avoid using autocomplete if I'm learning a new programming language.
2. Component prompting
In what I like to call component prompting, you describe a function, module, or file in natural language and the LLM generates it. You're no longer writing code line by line, you're specifying the intent of a contained unit. The major change from tab autocomplete is that you are prompting, i.e. writing the intent of a program in plain English. Examples of this would be "Create a React component that displays a sortable table with pagination." or pasting code and error messages and then asking the LLM to "fix the code".
I like to think of this as a separate layer for two reasons:
-
For the majority of the time I have used LLM-based coding (before agents were a thing), the LLM-instance I had running was in many cases separate from the coding environment. Most of the time it was literally a separate browser window. The LLM didn't have access to the whole codebase as is often the case now with large context windows.
-
Because of the point above, the LLMs could only make limited changes to the code base. It often required careful and detailed explanation about the data flow and how the files were structured. In other words, you still need to have context about the structure and data flow of the code. It was also often the case that the code needed some additional modifications, which was often the fastest to manually do yourself.
This is where things get interesting from a learning perspective. When I prompt a component, I'm thinking at a higher level of abstraction than when I'm writing code manually or using tab autocomplete. I'm reasoning about interfaces rather than implementation details. In a way this can be powerful, since it forces you to think clearly about what you want to build before worrying about how it gets built. But it also means you might not notice suboptimal coding choices, subtle bugs in edge cases or performance issues that you would have caught if you'd written the code yourself.
3. Agent-driven development
In agent-driven development you provide a rough description of what you want to build, and the LLM handles planning, file structure, and implementation across multiple files. The agents often have the entire project as context to drive development. In many cases the agents also handle everything else that comes with software engineering: setting up testing frameworks, configuring build tools, writing CI pipelines, and deploying.
This is what the developments made during 2025 have enabled. The LLMs are "proactive" in the sense that they can be sent out and work on something until they are done without needing much intervention at all from a human supervisor. Boris Cherny, the creator of Claude Code, describes how he sometimes manages Claude Code sessions from his phone when they eventually need input from him. Additionally, the agents can work on the same project with different tasks in parallel.
The upsides of this are clear and many software engineers have reported development speed increasing by a lot. You can go from idea to working prototype in minutes. If managed correctly and carefully reviewing pull requests, agent-driven development can have a very positive impact.
However, there are some downsides which quite quickly become clear. In the cases where an agent builds the majority of a project, your understanding of the codebase can be paper-thin. The agent might make architectural decisions you wouldn't have made, for example using patterns you are unfamiliar with or structuring the data flow in ways that will be painful to modify later.
To sum this section up I think it's important to notice what happens when you move up through the layers. You write less and read more. The cognitive load becomes smaller and smaller and shifts from composing code to reviewing it. This led me to the second realization this blog consists of, which I didn't fully appreciate at first: reading and writing code are very different in nature.
Reading ≠ Writing Code
Although this fact might be obvious to many people, I think this was personally one of the most important realizations I have had in the past year about programming: reading code is very different from writing code. I have started seeing it as fundamentally two different skills. It's two different capabilities and they involve different parts of the brain.
Let's be clear on what we mean by writing code. Considering the abstraction layers explored above, where does the line between writing code and prompting go? I think this is a very important question and something worth pondering about if you code on a regular basis.
Personally, I have found the line to be just around tab autocomplete. By writing most of the files using tab autocomplete, I'm able to maintain an idea of the structure and the data flow in the application. When using tab autocomplete, the focus still lies on the next line of code, whether it is correct and makes sense in a larger context.
Let's further break down what skills reading and writing code consist of. When you write code, you're forced to think through problem decomposition, breaking down what you want into implementable steps. You must consider how different components of code should fit together, what interfaces make sense, where boundaries should exist.
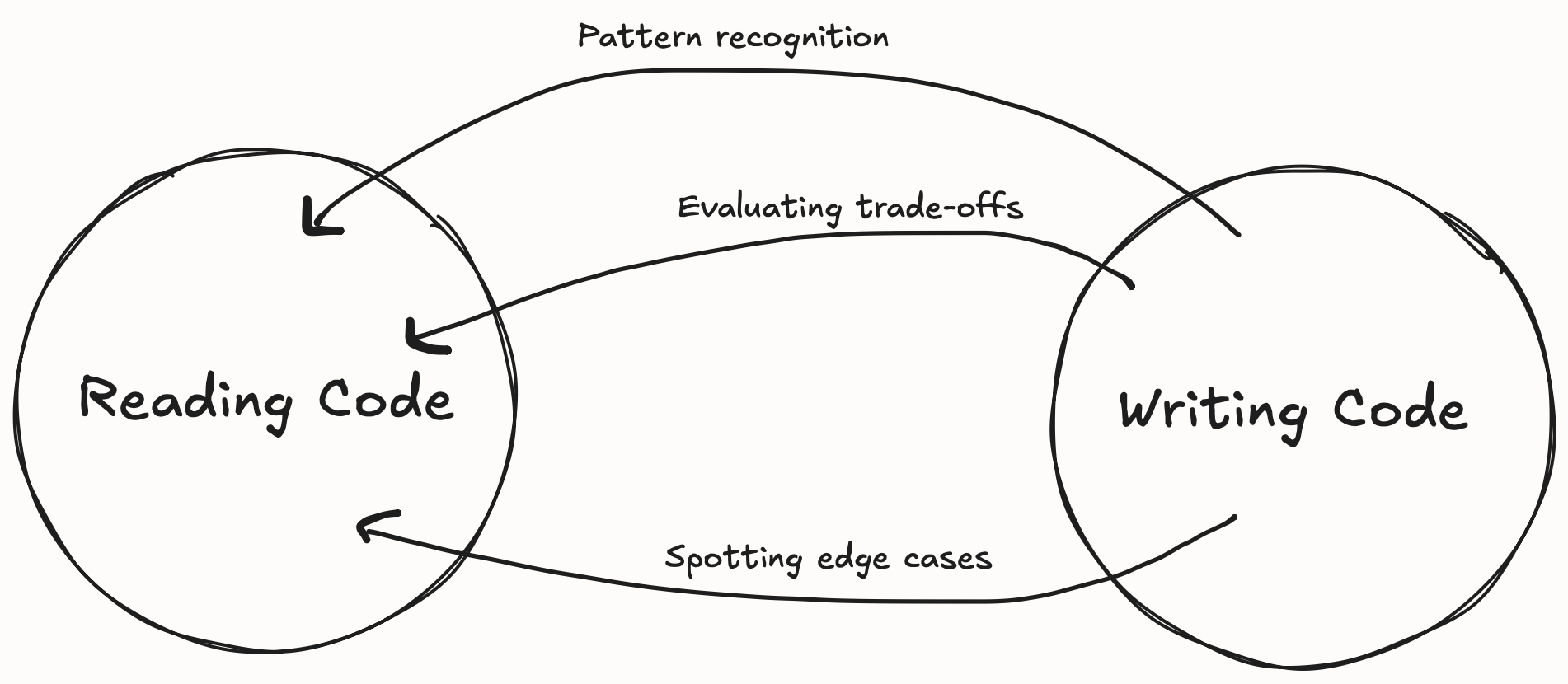
Once you've written something, reading similar code becomes easier because you recognize the patterns you've used yourself. You understand why someone might structure code a certain way because you've faced those same constraints. But the reverse doesn't hold as strongly. You can read and comprehend code, trace its execution, understand what it does and that it works without errors, without ever understanding why the decisions were made and how you could potentially add new functionality.
Although reading and writing go hand-in-hand, I think there are certain skills you get from writing code which can help you to read code better, but that the reverse doesn't hold true nearly as strongly. This asymmetry is at the heart of why I think relying too heavily on LLM-generated code can be problematic for learning. When the model writes code and you read it, you get the reading practice but miss the writing practice.
I have tested this on myself several times. After solving a problem with an LLM and then understanding (whatever that may mean) the solution, I asked the model to quiz me on it. Questions like: Can you describe the data flow? Why did you pick this data structure? How would you extend this to handle X? There was this hollowness to my understanding of the code which wasn't there if I had written the code myself.
Closing Thoughts
I think the most important skill isn't learning to prompt better or mastering the latest agent tool. It's developing the self-awareness to know when to use these tools and when not to use them. I believe the developers who will thrive the most won't be defined by the tools they use, but by knowing when to use them and when not to.
Casimir Rönnlöf, February 2026